
Enhancing Book Labelling with GPT4

Along with everyone else we at Huey Books saw in ChatGPT the massive potential of large language models and were eager to explore its potential for our children's book recommender Huey the Bookbot.
We carefully created a series of exciting experiments and dove right in. Our goal? To tackle one of our greatest challenges: streamlining the time-consuming manual process of describing and labelling books.
The system we devised uses a combination of semi-structured and semi-reliable text, including data from different classification systems and marketing material, to provide context for the language model. The GPT-4 powered system has labeled the majority of our books in the last few months.
A brief history of the labelling at Huey Books
From the beginning Huey has been using a combination of machine learning technology and human experts to label books. Through extensive user research and workshops with experts and librarians we came up with our internal “Hues” used to label the tone of children’s books, e.g., “Silly & Charming” or “Funny & Quirky”. Our hues are the foundation of our recommendations and we’ve worked hard to describe these in detail - mainly so that our editors were applying labels consistently. There have been many hotly debated discussions on what a term really means and how that relates to the tone of a book. Those discussions have been crucial to the work we have done with GPT4.
Our original method for classifying books involved transforming descriptive text and cover image data into a vector space, which is a way to represent complex information in a more manageable form. We then used clustering, a technique that groups similar books together, after which our human experts assigned the appropriate "Hues" to the groups of books.
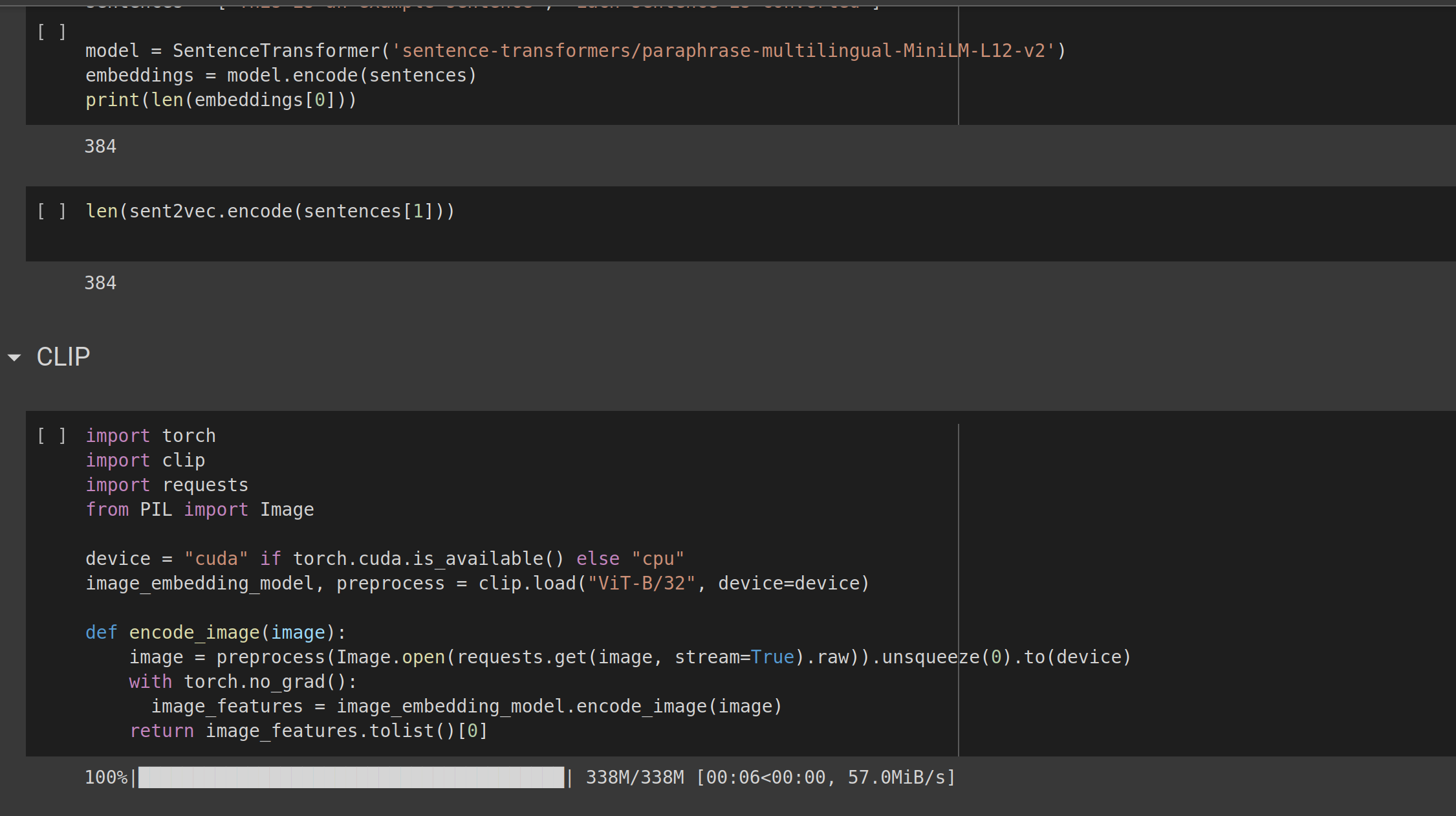
Our next version used supervised learning with a neural network classifier instead of clustering with human labelling. Our existing data was used to train the neural network so it could directly assign Hues and other labels to individual books. Human experts continue to play a crucial role in verifying labels, crafting summaries, providing parental notes, and assessing reading ability according to age-appropriate guidelines.
Initially we spent a few hours validating the idea using ChatGPT directly. We would ask questions about old and new books to get an idea for what innate knowledge the large language model had. As expected, details about popular books like the Harry Potter series were extremely well known, while details from newer or less popular books were often incorrect. This hallucination can be addressed by providing ChatGPT with context on a book - the raw information we had collected from various sources. We started with simple questions like picking the most relevant genres from a list given all our existing context, and kept adding requirements including summarising the book for parents, creating content advisory notes and more.
We came to the conclusion that it was well worth investing our time to take this further and to build out infrastructure to support experimentation.

To help with experimentation we modified our admin tool, adding a “Get labels” button that would call an endpoint on our application that would interact with OpenAI’s GPT-4 model and show the results alongside the existing labels for comparison. Although librarians and teachers use our admin tool this feature was only available to our team!
Huey’s backend application is written in Python and runs on Google’s Cloud Platform (GCP). We investigated several options for interacting with the OpenAI APIs and decided to simply use the OpenAI’s official Python library. To iterate quickly, and to allow the whole team to work on the prompt we used a Google Doc for the prompt itself.
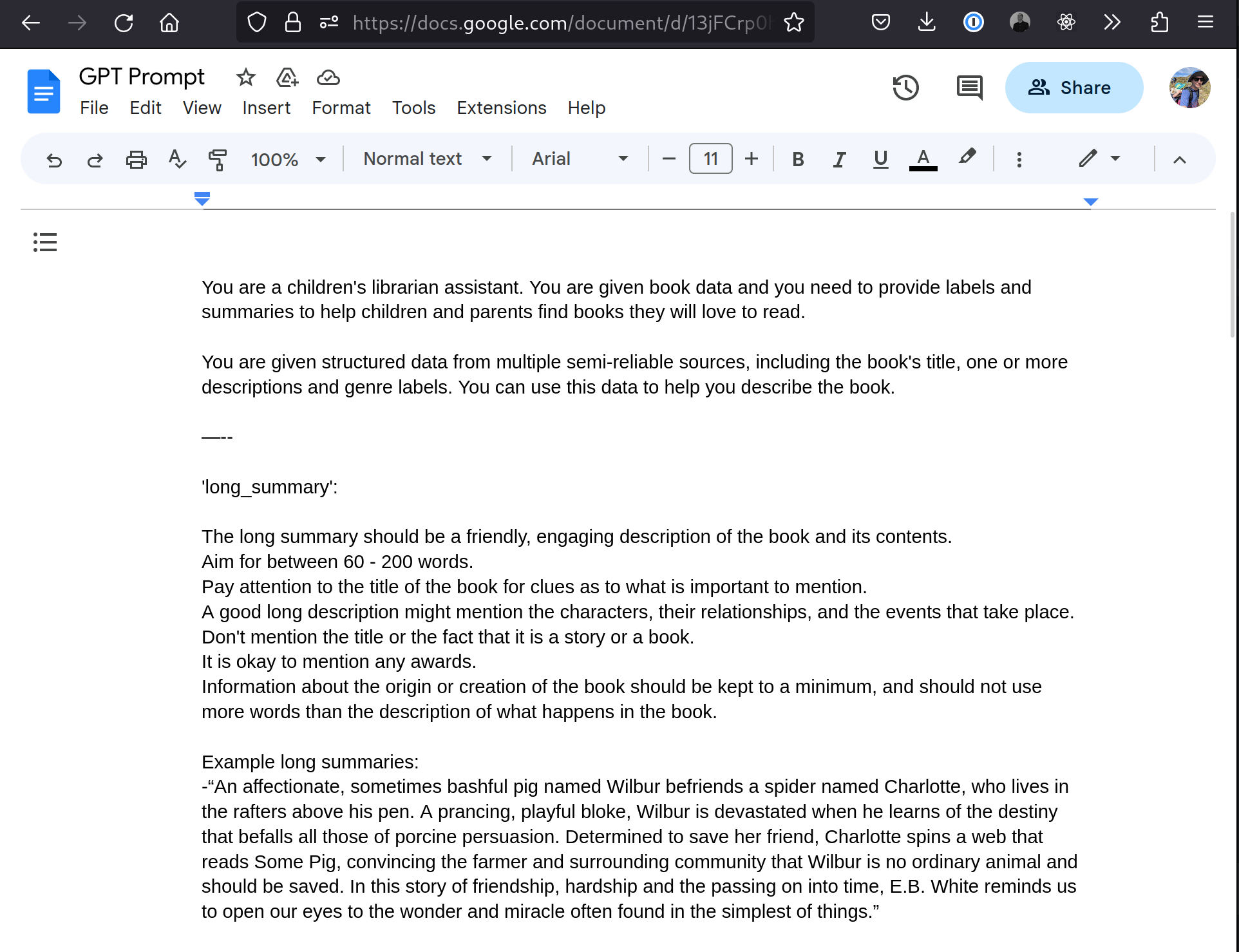
Our FastAPI application would access the Google Doc when a label was requested. In the API we combine the prompt with all the data we had for the book itself. The prompt ended up being 7 pages long! We used ChatCompletion from OpenAI’s official python library with the GPT-4 model. We request the large language model (LLM) to respond in JSON format, and we validate the response using Pydantic - getting GPT-4 to try fix any issues if the response is invalid. The response would be passed back to our admin tool, for our review.
After several weeks of careful experimentation we kept adding more responsibilities to the LLM, eventually getting it to generate long and short summaries, content warning notes as well as a multitude of label information.
Hallucination - where the language model just “makes stuff up” wasn’t an issue because of the large amount of context we provided. This often included data shaped by different systems of classifications such as the Library of Congress or THEMA.
Unfortunately lots of our descriptive data was marketing material for a book e.g., “New best seller from award winning author …”. With clear instructions GPT-4 was able to take this semi-structured, semi-reliable text and extract accurate labels and great descriptions.
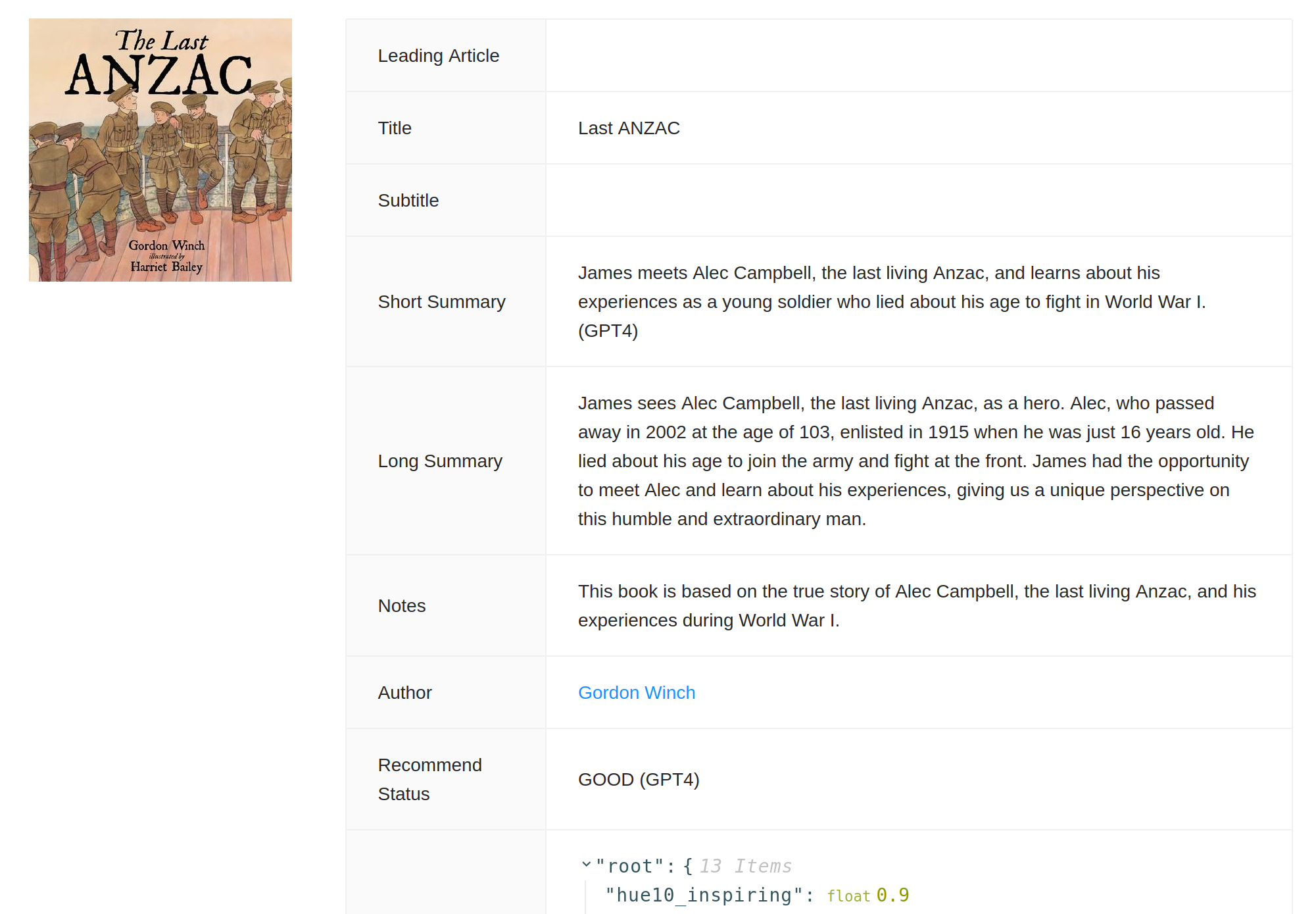
After several weeks of experimentation, the team found that GPT-4 was able to provide labels and descriptions that were indistinguishable from human labellers at a fraction of the cost. We promoted the experiment to production, and have been able to label many more books.
Happy reading.

